Spark and Hadoop
Published:
This is my personal notes for Spark and Hadoop.
解决问题的层面不一样
Hadoop和Spark两者都是大数据框架,但是各自存在的目的不尽相同。
对标的SQL层面分别是 Hive(Hive on MR, Hive on Spark) 和 SparkSQL。
- Hadoop
- Hadoop实质上是解决大数据大到无法在一台计算机上进行存储、无法在要求的时间内进行处理的问题,是一个分布式数据基础设施。
- MapReduce,通过简单的Mapper和Reducer的抽象提供一个编程模型,可以在一个由几十台上百台的机器上并发地分布式处理大量数据集,而把并发、分布式和故障恢复等细节隐藏。Hadoop复杂的数据处理需要分解为多个Job(每个Job包含一个Mapper和一个Reducer)组成的有向无环图。
- Hive, 提供SQL自动生成MapReduce任务处理HDFS中的数据, Hive的本质是把SQL语句转化成了MapReduce程序。
- HDFS,它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,通过将块保存到多个副本上,提供高可靠的文件存储。
- Spark
- Spark允许程序开发者使用有向无环图(DAG)开发复杂的多步数据管道。而且还支持跨有向无环图的内存数据共享,以便不同的作业可以共同处理同一个数据。是一个专门用来对那些分布式存储的大数据进行处理的工具,它并不会进行分布式数据的存储, 存储可以依赖HDFS。可将Spark看作是Hadoop MapReduce的一个替代品。
两者可合可分
Hadoop除了提供MapReduce的数据处理功能, 还有HDFS分布式数据存储系统。所以我们完全可以抛开Spark,仅使用Hadoop自身的MapReduce来完成数据的处理。
Spark也不是非要依附在Hadoop身上才能生存。但它没有提供文件管理系统,所以,它必须和其他的分布式文件系统进行集成才能运作。我们可以选择Hadoop的HDFS,也可以选择其他的基于云的数据系统平台。但Spark默认来说还是被用在Hadoop上面的,被认为它们的结合是最好的选择。
Spark优势
1 处理速度
Spark vs MapReduce ≠ 内存 vs 磁盘
其实Spark和MapReduce的计算都发生在内存中,区别在于:
MapReduce通常需要将计算的中间结果写入磁盘,然后还要读取磁盘,从而导致了频繁的磁盘IO。
Spark则不需要将计算的中间结果写入磁盘,这得益于Spark的RDD(弹性分布式数据集,很强大)和DAG(有向无环图),其中DAG记录了job的stage以及在job执行过程中父RDD和子RDD之间的依赖关系。中间结果能够以RDD的形式存放在内存中,且能够从DAG中恢复,大大减少了磁盘IO。
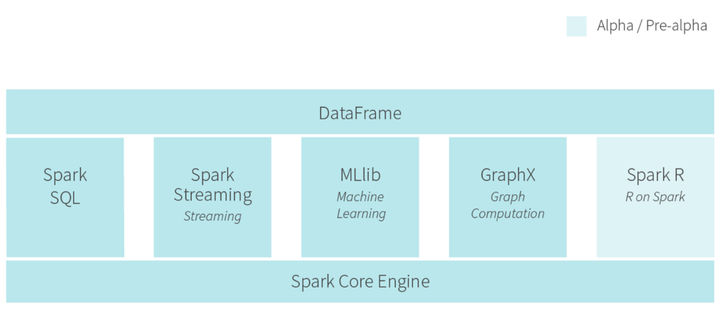
2 多样性功能
- Spark框架为批处理(Spark Core),交互式(Spark SQL),流式(Spark Streaming),机器学习(MLlib),图计算(GraphX)提供了一个统一的数据处理平台。