
Elasticsearch
Published:
This is my personal notes for elasticsearch.
Introduction
Elasticsearch是一个分布式的 RESTful 风格的搜索和数据分析引擎, Kibana是一个方便的ES插件
python操作ES也十分方便, 导入es包,实例化es之后便可以进行各种操作
Elasticsearch建立在Lucene基础之上,底层采用Lucene来实现文件的读写操作, Elasticsearch基于lucene,又不简单地只是lucene,它完美地将lucene与分布式系统结合,既利用了lucene的检索能力,又具有了分布式系统的众多优点。
Elasticsearch通过引入分片概念,成功地将lucene部署到分布式系统中,增强了系统的可靠性和扩展性。
Elasticsearch通过定期refresh lucene in-momory-buffer中的数据,使得ES具有了近实时的写入和查询能力。
Elasticsearch通过引入translog,多副本,以及定期执行flush,merge等操作保证了数据可靠性和较高的存储性能。
Elasticsearch通过存储_source字段结合verison字段实现了文档的局部更新,使得ES的使用方式更加灵活多样。
ES存储方式

不同于MySQL和HBase, ES的存储方式是索引存储
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引 ⇒ 类型 ⇒ 文档 ⇒ 字段(Fields)
一个 Elasticsearch 集群可以包含多个索引(数据库),其中包含了很多类型(表)。这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。每条记录都是一个文档, 用JSON序列化。
ES索引
Elasticsearch最关键的就是提供强大的索引能力了, Elasticsearch索引的精髓:一切设计都是为了提高搜索的性能, 另一层意思:为了提高搜索的性能,难免会牺牲某些其他方面,比如插入/更新。
往Elasticsearch里插入一条记录,其实就是直接PUT一个json的对象,这个对象有多个fields,比如name, sex, age, interests,那么在插入这些数据到Elasticsearch的同时,Elasticsearch还自动为这些字段建立索引–倒排索引,因为Elasticsearch最核心功能是搜索。
倒排索引:
传统的我们的检索是通过文章,逐个遍历找到对应关键词的位置。
而倒排索引,是通过分词策略,形成了词和文章的映射关系表,这种词典+映射表, 即为倒排索引。
有了倒排索引,就能实现 o(1)时间复杂度的效率检索文章了,极大的提高了检索效率。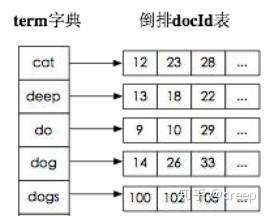
ES写入方案
分布式设计
为了支持对海量数据的存储和查询,Elasticsearch引入分片的概念,一个索引被分成多个分片,每个分片可以有一个主分片和多个副本分片,每个分片副本都是一个具有完整功能的lucene实例。分片可以分配在不同的服务器上,同一个分片的不同副本不能分配在相同的服务器上。
在进行写操作时,ES会根据传入的_routing参数(或mapping中设置的_routing, 如果参数和设置中都没有则默认使用_id), 按照公式 shard_num=hash(\routing)%num_primary_shards,计算出文档要分配到的分片,在从集群元数据中找出对应主分片的位置,将请求路由到该分片进行文档写操作。
近实时性
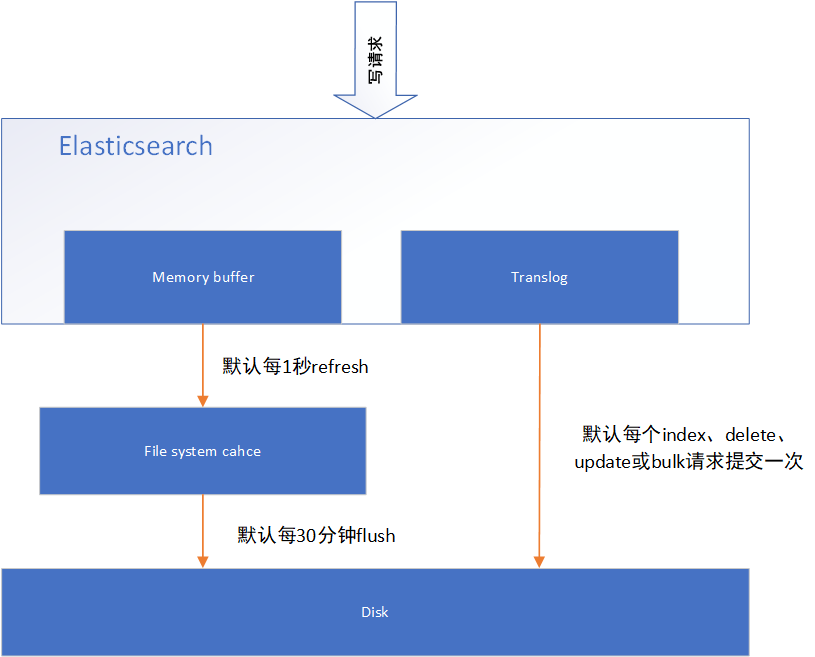
如果每次一条数据写入内存后立即写到硬盘文件上,会严重降低es的性能。因此es在设计时在memory buffer和硬盘间加入了Linux的页面高速缓存(File system cache)来提高es的写效率。
当写请求发送到es后,es将数据暂时写入memory buffer中,此时写入的数据还不能被查询到。默认设置下,es每1秒钟将memory buffer中的数据refresh到Linux的File system cache,并清空memory buffer,此时写入的数据就可以被查询到了。
对于需要写入后实时查询的数据,可以通过手动refresh操作将memory buffer的数据立即写入到File system cache。
数据存储可靠性
1 translog
File system cache依然是内存数据,一旦断电,则数据全部丢失。因此需要通过translog来保证即使因为断电File system cache数据丢失,es重启后也能通过日志回放找回丢失的数据。
translog默认设置下,每一个index、delete、update或bulk请求都会直接fsync写入硬盘。为了保证translog不丢失数据,在每一次请求之后执行fsync确实会带来一些性能问题。对于一些允许丢失几秒钟数据的场景下,可以通过设置index.translog.durability和index.translog.sync_interval参数让translog每隔一段时间才调用fsync将事务日志数据写入硬盘。
2 flush
每30分钟ES会触发一次flush操作,File system cache中的数据会持久化到disk中 translog中的数据会被清空。
写入流程
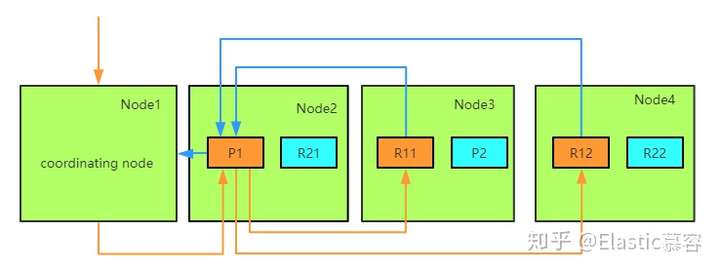
ES的任意节点都可以作为协调节点(coordinating node)接受请求,当协调节点接受到请求后进行一系列处理,然后通过_routing字段找到对应的primary shard,并将请求转发给primary shard, primary shard完成写入后,将写入并发发送给各replica, raplica执行写入操作后返回给primary shard, primary shard再将请求返回给协调节点。大致流程如下图:
ES索引数据过多如何调优,部署
(1) 动态索引层面
基于模板+时间+rollover api 滚动创建索引,举例:设计阶段定义:blog 索引的模板格式为:blog_index_时间戳的形式,每天递增数据。
这样做的好处:不至于数据量激增导致单个索引数据量非常大,接近于上线 2 的32 次幂-1,索引存储达到了 TB+甚至更大。一旦单个索引很大,存储等各种风险也随之而来,所以要提前考虑+及早避免。
(2) 存储层面
冷热数据分离存储,热数据(比如最近 3 天或者一周的数据),其余为冷数据。
对于冷数据不会再写入新数据,可以考虑定期 force_merge 加 shrink 压缩操作,节省存储空间和检索效率。
(3) 部署层面
一旦之前没有规划,这里就属于应急策略。
结合 ES 自身的支持动态扩展的特点,动态新增机器的方式可以缓解集群压力
注意:如果之前主节点等规划合理,不需要重启集群也能完成动态新增的。
在并发情况下,Elasticsearch如果保证读写一致
可以通过版本号使用乐观并发控制(OCC),以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
对于写操作,一致性级别支持quorum/one/all,默认为quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
对于读操作,可以设置replication为sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置replication为async时,也可以通过设置搜索请求参数_preference为primary来查询主分片,确保文档是最新版本。
Note:
OCC是用来解决写-写冲突的无锁并发控制,认为事务间争用没有那么多,所以先进行修改,在提交事务前,检查一下事务开始后,有没有新提交改变,如果没有就提交,如果有就放弃并重试。乐观并发控制类似自选锁。乐观并发控制适用于低数据争用,写冲突比较少的环境。
MVCC是用来解决读-写冲突的无锁并发控制,也就是为事务分配单向增长的时间戳,为每个修改保存一个版本,版本与事务时间戳关联,读操作只读该事务开始前的数据库的快照。 这样在读操作不用阻塞写操作,写操作不用阻塞读操作的同时,避免了脏读和不可重复读。
搜索数据的底层原理
查询过程大体上分为查询和取回这两个阶段,广播查询请求到所有相关分片,并将它们的响应整合成全局排序后的结果集合,这个结果集合会返回给客户端。
1 查询阶段
- a 当一个节点接收到一个搜索请求,这这个节点就会变成协调节点,第一步就是将广播请求到搜索的每一个节点的分片拷贝,查询请求可以被某一个主分片或某一个副分片处理,协调节点将在之后的请求中轮训所有的分片拷贝来分摊负载。
- b 每一个分片将会在本地构建一个优先级队列,如果客户端要求返回结果排序中从from 名开始的数量为size的结果集,每一个节点都会产生一个from+size大小的结果集,因此优先级队列的大小也就是from+size,分片仅仅是返回一个轻量级的结果给协调节点,包括结果级中的每一个文档的ID和进行排序所需要的信息。
- c 协调节点将会将所有的结果进行汇总,并进行全局排序,最总得到排序结果。
2 取值阶段
- a 查询过程得到的排序结果,标记处哪些文档是符合要求的,此时仍然需要获取这些文档返回给客户端
- b 协调节点会确定实际需要的返回的文档,并向含有该文档的分片发送get请求,分片获取的文档返回给协调节点,协调节点将结果返回给客户端。
实例展示
from elasticsearch import Elasticsearch
es = Elasticsearch(['mbd-rec-elasticsearch-online006-bdwg.xxx.xxx:xxxx'], port=9200) #集群的一个节点
ES查询
example 1
“must”==and, ‘should’==or, ‘range’==between, ‘exists’==非空, ‘match_phrase’==’==’
body2={ "query": { "bool": { "must": [ {"range": { "tag_cnt": {"gte": "1","lt": None}}}, {"range": {"duration": {"gte": 61, "lt": 900}}}, {"exists": {"field": "father_id"}}, {"match_phrase": { "access": { "query": True } } }, {"match_phrase": { "soft_porn": { "query": False } } }, { "bool": { "should": [ {"match_phrase": { "lchannel": { "query": 1 } } }, {"match_phrase": { "lchannel": { "query": 2 } } }, {"match_phrase": { "lchannel": { "query": 3 } } }, {"match_phrase": { "lchannel": { "query": 4 } } }, {"match_phrase": { "lchannel": { "query": 6 } } }, {"match_phrase": { "lchannel": { "query": 15 } } }, {"match_phrase": { "lchannel": { "query": 31 } } } ], "minimum_should_match": 1 } } ] } } } page2 = es.search(index='stv', doc_type='stv', body=body2) DS_short=page2['hits']['total']example 2
这里增加了聚合操作’aggs’,相当于distinct count(‘father_id’), 统计符合条件的 father_id 数量
body4={ "aggs": { "by_fatherId": { "cardinality": { "field": "father_id" } } }, "query": { "bool": { "must": [ {"range": { "home_cps_time": {"gte": "now-7d/d","lt": "now"}}}, {"range": {"album": {"gte": 0, "lt": 1}}}, {"exists": {"field": "father_id"}}, ] } } } page4 = es.search(index='stv', doc_type='stv', body=body4) corpus_long2=page4['aggregations']['by_fatherId']['value']ES写入
1 es更新(update)操作, 这里需要id已经在es中存在,会覆盖原来的数据, body可传入各种形式的json数据
body = {"doc": { 'lidCount_online': lidCount_online, 'sidCount_online': sidCount_online, 'lidCount_rate': lidCount_rate, 'sidCount_rate': sidCount_rate } } es.update(index='corpus_daily_statistics', doc_type='st', id=date, body=body)2 es插入(index)操作, 这里新建一个id为Today的es记录,body可传入各种形式的json数据
如 {‘A’:{‘B’:[{‘C’:’D’},{‘E’:’F’}]}}es.index(index='core_indicator_daily_analysis', doc_type='st', id=Today, body=data)