
Java Foundation
Published:
This is my personal notes for Java Foundation.
Introduction
本文介绍Java基础知识
Java 三大特性
封装:
1.定义:隐藏对象的属性和实现细节,仅对外公开接口, 控制在程序中属性的读和修改的访问级别。
2.封装的目的是:增强安全性和简化编程,使用者不必了解具体的实现细节,而只是要通过外部接口,一特定的访问权限来使用类的成员。
3.封装的基本要求是:把所有的属性私有化,对每个属性提供getter和setter方法,如果有一个带参的构造函数的话,那一定要写一个不带参的构造函数。在开发的时候经常要对已经编写的类进行测试,所以在有的时候还有重写toString方法,但这不是必须的。
继承:
1.目的:实现代码的复用。
2.介绍:当两个类具有相同的特征(属性)和行为(方法)时,可以将相同的部分抽取出来放到一个类中作为父类,其它两个类继承这个父类。继承后子类自动拥有了父类的属性和方法,但特别注意的是,父类的私有属性和构造方法并不能被继承。另外子类可以写自己特有的属性和方法,目的是实现功能的扩展,子类也可以复写父类的方法即方法的重写。子类不能继承父类中访问权限为private的成员变量和方法。子类可以重写父类的方法,及命名与父类同名的成员变量。
多态:
1.概念:相同的事物,调用其相同的方法,参数也相同时,但表现的行为却不同。
2.Java实现多态有三个必要条件:继承、重写、向上转型。
继承:在多态中必须存在有继承关系的子类和父类。
重写:子类对父类中某些方法进行重新定义,在调用这些方法时就会调用子类的方法。
向上转型:在多态中需要将子类的引用赋给父类对象。
(Father f = new Child1(); f = new Child2())
只有满足了上述三个条件,我们才能够在同一个继承结构中使用统一的逻辑实现代码处理不同的对象,从而达到执行不同的行为。
3.多态的实现方式:
a 基于继承实现的多态
和多个子类继承一个父类并对某些方法进行重写。
b 基于接口实现的多态
不同的类体实现接口并覆盖接口中同一方法。
在接口的多态中,指向接口的引用必须是指定这实现了该接口的一个类的实例程序,在运行时,根据对象引用的实际类型来执行对应的方法。
继承都是单继承,只能为一组相关的类提供一致的服务接口。但是接口可以是多继承多实现,它能够利用一组相关或者不相关的接口进行组合与扩充,能够对外提供一致的服务接口。所以它相对于继承来说有更好的灵活性。
4.多态性主要表现在如下两个方面:
a 方法重载.
通常指在同一个类中,相同的方法名对应着不同的方法实现,但是方法的参数不同.
b 方法重写.
通常指在不同类(父类和子类)中,允许有相同的变量名,但是数据类型不同;也允许有相同的方法名,但是对应的方法实现不同.
String,StringBuilder, StringBuffer
String (不可变,线程安全)
String类是final类,也即意味着String类不能被继承
String是用char[]存储的, 其属性字段基本都是final的, 所以是不可变的, 线程安全
无论是sub、concat还是replace操作都不是inplace操作,而是重新生成了一个新的字符串对象
String直接赋值和new String()的区别
直接赋值
String str1 = "hello"; String str2 = "hello"; String str3 = "world";生成了2个对象
这样创建字符串,首先会去常量池里找有没有这个字符串,有就直接指向常量池的该字符串,没有就先往常量池中添加一个,再指向它。图解: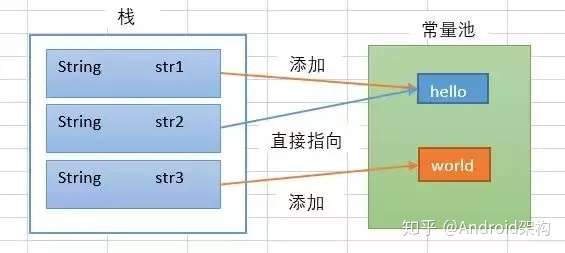
用new创建
String str1 = new String("hello"); String str2 = new String("hello"); String str3 = new String("world");生成了5个对象
new一个字符串时,做了两件事。首先在堆中生成了该字符串对象,然后去看常量池中有没有该字符串,如果有就不管了,没有就往常量池中添加一个。图解: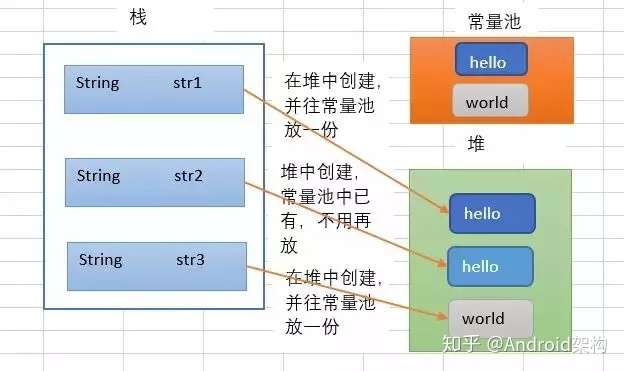
这两种方式创建的对象一种在常量池中一种在堆中, 所以用==比较会是false
StringBuilder(可变,线程不安全)
底层存储数据的Char[]数组,初始化时,该数组的长度是16。如果构造函数有新传入字符转str,则16基础上加str.length.
添加字符串的过程: 先检查内部char[]数组是否需要扩容, 如需要扩容则进行扩容,然后将原来元数据copy到新数组中。再将新添加的元数据加入到新char[]数组中。
String的+=操作底层是使用StringBuilder完成的
以下代码, JVM会优化成StringBuilder进行append, 循环10000次会在堆中new出10000个对象。
public class Main { public static void main(String[] args) { String string = ""; for(int i=0;i<10000;i++){ string += "hello"; } } // JVM执行方式 StringBuilder str = new StringBuilder(string); str.append("hello"); str.toString(); }而如果直接使用StringBuilder, 则只会new一次对象, append操作是在原有对象的基础上进行的, 所占的资源要比上面小得多
public class Main { public static void main(String[] args) { StringBuilder stringBuilder = new StringBuilder(); for(int i=0;i<10000;i++){ stringBuilder.append("hello"); } } }StringBuffer (可变,线程安全)
StringBuffer和StringBuilder成员属性以及成员方法基本相同, 不同的是StringBuffer的方法前面都加上了synchronized, 所以StringBuffer是线程安全的。
常见面试题
a String a = “hello2”; String b = “hello” + 2; System.out.println((a == b));
输出结果为:true。原因很简单,”hello”+2在编译期间就已经被优化成”hello2”,因此在运行期间,变量a和变量b指向的是同一个对象。
b String a = “hello2”; String b = “hello”; String c = b + 2; System.out.println((a == c));
输出结果为:false。由于有符号引用的存在,所以 String c = b + 2; 不会在编译期间被优化,不会把b+2当做常量来处理,因此这种方式生成的对象保存在堆上。而a保存在常量池中。
c String a = “hello2”; final String b = “hello”; String c = b + 2; System.out.println((a == c));
输出结果为:true。对于被final修饰的变量,会在class文件常量池中保存一个副本,也就是说不会通过连接而进行访问,对final变量的访问在编译期间都会直接被替代为真实的值。所以a和c都保存在常量池中。
d String str = new String(“abc”)创建了多少个对象?
2个, 堆中1个, 常量池1个
e 1)和2)哪个更高效?
public class Main { public static void main(String[] args) { String str1 = "I"; //str1 += "love"+"java"; 1) str1 = str1+"love"+"java"; //2) } }两者都会调用StringBuilder进行append, 1)的”love”+”java”会在编译时被优化成”lovejava”, 而 2)会append两次。所以1)更高效。
关键字
1 static
a 修饰成员变量
static关键字可以修饰成员变量,它所修饰的成员变量不属于对象的数据结构,而是属于类的变量,通常通过类名来引用static成员。
当创建对象后,成员变量是存储在堆中的,而static成员变量和类的信息一起存储在方法区, 而不是在堆中
一个类的static成员变量只有“一份”(存储在方法区)
举例: 以下代码输出1, 2, 3, num对所有对象只有一份
class People { private int age; private static int num; public People(int age) { this.age = age; System.out.print(++num); } } public class StaticDemo { public static void main(String[] args) { People p1 = new People(18); People p2 = new People(19); People p3 = new People(20); } }b 修饰方法
static修饰的方法不需要针对某些对象进行操作,其运行结果仅仅与参数有关,调用的话直接用类名就可以调用了。(new 一个对象进行调用其实也可以)
static方法中不能直接调用non-static方法, 但是可以间接通过对象的引用调用其non-static方法。
class Test2{ public void method2(){ System.out.println("HelloWorld2"); } } class Test1 { public void method0(){ System.out.println("HelloWorld0"); } public static void method1() { System.out.println("HelloWorld1"); } public static void main(String[] args) { // this.method0(); // 静态方法中不能用this, super等直接调用非静态方法 new Test1().method0(); // 用对象的引用调用非静态方法method0 Test1.method1(); // 直接用类名调用静态方法method1 new Test2().method2(); // 用对象的引用调用非静态方法method2 } // 输出 // HelloWorld0 // HelloWorld1 // HelloWorld2 }c static块
它是随着类的加载而执行,只执行一次,并优先于主函数。具体说,静态代码块是由类调用的。类调用时,先执行静态代码块,然后才执行主函数的。
静态代码块其实就是给类初始化的,而构造代码块是给对象初始化的。
静态代码块中的变量是局部变量,与普通函数中的局部变量性质没有区别。
一个类中可以有多个静态代码块class Test1 { static int cnt=6; static{ cnt+=9; } public static void main(String[] args) { System.out.println(cnt); } static{ cnt/=3; } } // 输出 // 5d static类
Java 的静态类只能是内部类, 其中的静态方法和成员可以直接通过内部类名在当前类被调用
class Test1 { private static class class1{ static int i = 100; } public static void main(String[] args) { System.out.println(class1.i); } } // 输出 // 100静态内部类和非静态内部类的区别:
1.是否能拥有静态成员 静态内部类可以有静态成员(方法,属性),而非静态内部类则不能有静态成员(方法,属性)。
2.访问外部类的成员 静态内部类只能够访问外部类的静态成员,而非静态内部类则可以访问外部类的所有成员(方法,属性)。
3.静态内部类和非静态内部类在创建时有区别 在类加载时JVM会把静态类放到方法区,被本类以及本类中所有实例所公用
创建方法的区别:
//假设类A有静态内部类B和非静态内部类C,创建B和C的区别为: A a=new A(); A.B b=new A.B(); A.C c=a.new C();
2 final
a 修饰变量
final意为不可改变,修饰成员变量时可以在声明时初始化或者在构造函数中初始化,修饰局部变量时在使用之前初始化。要是企图改变final修饰等变量值则会编译错误!
// 构造函数中初始化 class Test1 { public final int cnt; Test1(){ cnt = 4; } public static void main(String[] args) { System.out.println(new Test1().cnt); } } // 声明时初始化 class Test1 { public final int cnt = 4; public static void main(String[] args) { System.out.println(new Test1().cnt); } }b 修饰方法
final修饰等方法不能被重写。
class Test1 { public final void method1(){ System.out.println("this is method1"); } } class Test2 extends Test1 { // 报错, method1不能被重写 @Override public void method1() { super.method1(); } }c final修饰类
final修饰等类不能被继承,jdk中的一些基本类库被定义成final,例如String,Math,Integer等,这样可以防止对系统造成危害。
final class Test1 { } // 报错, class Test1不可被继承 class Test2 extends Test1{ public static void main(String[] args) { System.out.println("Hello"); } }
3 static final
static final修饰的成员变量被成为常量,必须声明时初始化并且不可被改变,static final常量在编译期间会被取代为其初始值。
4 super
访问父类的构造函数:可以使用 super() 函数访问父类的构造函数,从而委托父类完成一些初始化的工作。应该注意到,子类一定会调用父类的构造函数来完成初始化工作,一般是调用父类的默认构造函数,如果子类需要调用父类其它构造函数,那么就可以使用 super() 函数。
访问父类的成员:如果子类重写了父类的某个方法,可以通过使用 super 关键字来引用父类的方法实现。
public class SuperExample { protected int x; protected int y; public SuperExample(int x, int y) { this.x = x; this.y = y; } public void func() { System.out.println("SuperExample.func()"); } } public class SuperExtendExample extends SuperExample { private int z; public SuperExtendExample(int x, int y, int z) { super(x, y); // 调用父类的构造函数 this.z = z; } @Override public void func() { super.func(); // 调用父类的实现部分 System.out.println("SuperExtendExample.func()"); } }5 volatile
JAVA并发编程中的三个概念: 原子性, 可见性, 有序性
Synchronize和Lock可以保证这三个属性成立, Volatile可以保证可见性和一定的有序性, 不保证原子性。 但是Volatile开销更小。
原子性(不保证):
当某一个线程操作每一个业务的时候,不能被其他线程打断,不可以被分割操作,即整体一致性,要么同时成功,要么同时失败。
public class Atomic { volatile int num = 0; public void add() { num ++; } }线程1读取num = 0,修改为1,准备写回主内存时被挂起,线程2读取主内存的num = 0修改为1,然后写回。线程1被唤醒,快速的写入主内存,覆盖了已经写入的1,造成了数据丢失。 两次操作最终结果应该为2,但是为1。
自增操作可以使用AtomicInteger来保证原子性。
可见性:
Java提供了volatile关键字来保证可见性。当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
public class Shared { int a = 0; [volatile] bool flag = false; public void write() { a = 2; //1 flag = true; //2 } public void multiply() { if (flag) { //3 int ret = a * a;//4 } }线程1先调用 write,在线程调2用 multiply 时, 由于缓存的存在,flag可能还未写入内存, 所以multiply不会被执行。 此时会说一个线程对变量的修改对另一个线程不可见。
使用volatile:
在写入 volatile 变量时,之前写的(在缓存里的)变量都会被强制写入内存中
在读取 volatile 变量时,之前读的(在缓存里的)变量都会重新从内在中读取有序性
JMM是允许编译器和处理器对指令重排序的,但是规定了as-if-serial语义,即不管怎么重排序,程序的执行结果不能改变。
public class Shared { int a = 0; [volatile] bool flag = false; public void write() { a = 2; //1 flag = true; //2 } public void multiply() { if (flag) { //3 int ret = a * a;//4 } }上述代码中, 线程1先调用 write,由于指令重排, 在线程调2用 multiply 时, a=2还未执行,此时 ret=a*a会出错。Volatile可以保证共享变量不会被重排。
在JVM底层volatile是采用“内存屏障”来实现禁止特定类型的处理器重排序。加入volatile关键字时,会多出一个lock前缀指令,lock前缀指令实际上相当于一个内存屏障(也称内存栅栏)
Java可见性
| 修饰符 | 类内部 | 同个包(package) | 子类 | 其他范围 |
| public | Y | Y | Y | Y |
| protected | Y | Y | Y | N |
| 无修饰符 | Y | Y | N | N |
| private | Y | N | N | N |
Note: 无修饰符情况下,子类能否访问父类中无修饰符的变量/方法,取决于子类的位置。如果子类和父类在同一个包中,那么子类可以访问父类中的无修饰符的变量/方法,否则不行。
参数传递
Java 的参数是以值传递的形式传入方法中,而不是引用传递
传递对象时, 本质上是以值传递的方式传递地址
- Example1
class PassByValueExample { public static void main(String[] args) { Dog dog = new Dog("A"); func(dog); System.out.println(dog.getName()); // B } private static void func(Dog dog) { dog.setName("B"); } }将对象地址传进去, 修改之后对象属性会改变, 因为指向的是同一个对象
- Example2
class PassByValueExample { public static void main(String[] args) { Dog dog = new Dog("A"); System.out.println(dog.getObjectAddress()); // Dog@4554617c func(dog); System.out.println(dog.getObjectAddress()); // Dog@4554617c System.out.println(dog.getName()); // A } private static void func(Dog dog) { System.out.println(dog.getObjectAddress()); // Dog@4554617c dog = new Dog("B"); System.out.println(dog.getObjectAddress()); // Dog@74a14482 System.out.println(dog.getName()); // B } }将对象地址传进去, 重新赋值, 会覆盖之前的地址, 生成新对象
集合
(1) Array refers to a bunch of elements of same type stored in consecutive memory.
(2) ArrayList is dynamic array, the size of it can be changed, element could be add and remove from the list. (by Array)
(3) LinkedList is a linear data structure, in which elements are not stored in consecutive memory, each elements has 1 or more pointers to other elements. Typically, each element will be linked with the next element. (by doubly Linked List)
(4) HashMap is a data structure which stores data in key-value pair, to access a value, we must get its key, it is called HashMap because it uses Hashing, which means transfer a data block to a fixed range. (by array+LinkedList+Red-Black Tree)
(5) HashSet is a data structure which stores unique element in random order, no duplication is allowed, but there could be null. (by HashMap)
(6) TreeMap is a ordered Map which is implemented by Red-Black Tree, the key is stored in natural order. (By Red-Black Tree)
(7) TreeSet is a Ordered Set which is implemented by Red-Black Tree, the elements are stored in natural order. (By Red-Black Tree)

List
List 和 Array的区别:
虽然Array的随机访问和存储效率高,但其不可伸缩,初始化的时候必须指定Size,这使得数据动态更新很不方便。而List无需声明Size,方便插入删除
ArrayList
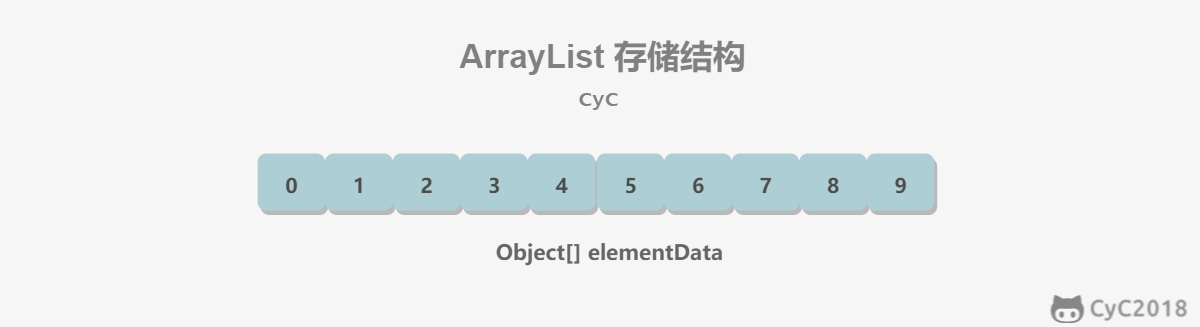
底层用Array实现,初始化为空的Array, add的时候size变为default的10 (懒加载)。
随机访问速度快O(1),中间位置插入删除速度慢(O(n))(需要调用System.arraycopy). 当有大量访问操作时,使用ArrayList
LinkedList
底层用doubly linked list实现,插入删除速度快(O(1)),随机访问速度慢(O(n)). 当有大量插入删除操作时,使用LinkedList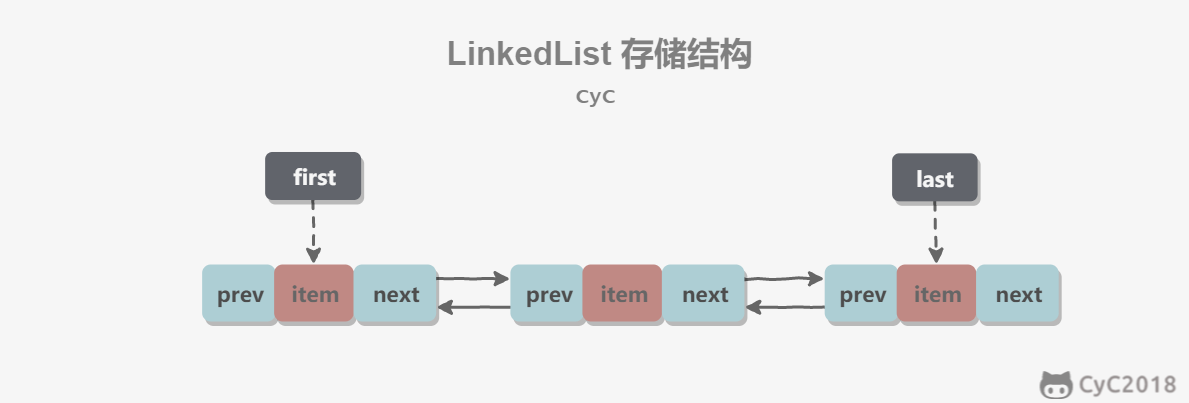
Vector
和 ArrayList 类似,但它是线程安全的。 和 ArrayList 不同, Vector 是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制;
Vector 每次扩容请求其大小的 2 倍(也可以通过构造函数设置增长的容量),而 ArrayList 是 1.5 倍。vector的替代方案:
可以使用 Collections.synchronizedList(); 得到一个线程安全的 ArrayList。List<String> list = new ArrayList<>(); List<String> synList = Collections.synchronizedList(list);
List<Integer> A=new ArrayList<>(); LinkedList<Integer> B=new LinkedList<>(); A.add(1) #在List末尾加入1 O(1) A.add(0,3) #在index=0的位置插入3,相当于insert O(n) A.remove(1) #删除索引为1的元素 O(n) A.remove(new Integer(1)) #删除元素 O(n) A.get(1) #取出索引为1的元素 O(1) A.addAll(A) #并入同类型的ArrayList A.size() #返回A中的元素个数 A.isEmpty() #判断是否为空 A.sort() #inplace 排序 A.subList(0,2) #返回index为0和1的元素 # LinkedList可以在头尾添加删除 # 由于LinkedList O(1)的插入删除速度, 可以当做栈、队列和双向队列使用 B.add(1) #在List末尾加入1 O(1) B.add(0,3) #在index=0的位置插入3,相当于insert O(n) B.remove(1) #删除索引为1的元素 O(n) B.remove(new Integer(1)) #删除元素 O(n), 需要先找到包含该元素的node,O(n)+O(1) B.get(1) #取出索引为1的元素 O(n), 同样需要从链表头开始遍历 B.addFirst() # O(1) B.addLast() # O(1) B.removeFirst() # O(1) B.removeLast()# O(1)Set
Set不包含重复的元素,这是Set最大的特点,也是使用Set最主要的原因。常用到的Set实现有 HashSet,LinkedHashSet 和 TreeSet。一般地,如果需要一个访问快速的Set,应该使用HashSet;当需要一个排序的Set,应该使用TreeSet;当需要记录下插入时的顺序时,应该使用LinedHashSet。
HashSet
委托给HashMap进行实现,实现了Set接口, 支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。 add()、remove()以及contains()等方法都是复杂度为O(1)
HashSet中的元素实际上是HashMap中的key, value设置为”Present”, HashMap key的唯一性保证了HashSet元素的唯一性, 添加元素时, 调用map.put(key, PRESENT), 如果元素存在返回oldValue, 对应的add方法返回false. 如果元素不存在更新HashMap并返回null, add方法返回true。 Set中的元素为HashMap的keySet。
TreeSet
委托给TreeMap(TreeMap实现了NavigableSet接口)进行实现,实现了NavigableSet接口(扩展的 SortedSet)
TreeSet是采用红黑树结构实现,元素是按顺序进行排列,但是add()、remove()以及contains()等方法都是复杂度为O(log (n))的方法,它还提供了一些方法来处理排序的set,如first()、 last()、 headSet()和 tailSet()等。此外,TreeSet不同于HashSet和LinkedHashSet,其所存储的元素必须是可排序的(元素实现Comparable接口或者传入Comparator),并且不能存放null值。
LinkedHashSet
是HashSet的子类,被委托给HashMap的子类LinkedHashMap进行实现,实现了Set接口
LinkedHashSet继承于HashSet,利用下面的HashSet构造函数即可,注意到,其为包访问权限,专门供LinkedHashSet的构造函数调用。LinkedHashSet性能介于HashSet和TreeSet之间,是HashSet的子类,也是一个hash表,但是同时维护了一个双链表来记录插入的顺序,基本方法的复杂度为O(1)。
Set<Character> B=new HashSet<>(); Set<Character> C=new TreeSet<>(); Set<Character> D=new LinkedHashSet<>(); B.add('a'); #添加元素 B.remove('a'); #删除元素 B.addAll(C) #B和C取并集 B.size() #返回B的元素个数 B.isEmpty() #判断是否为空 B.sort() #返回排序后的List B.clear() #清空set
Queue
LinkedList:可以用它来实现双向队列。
PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
Map
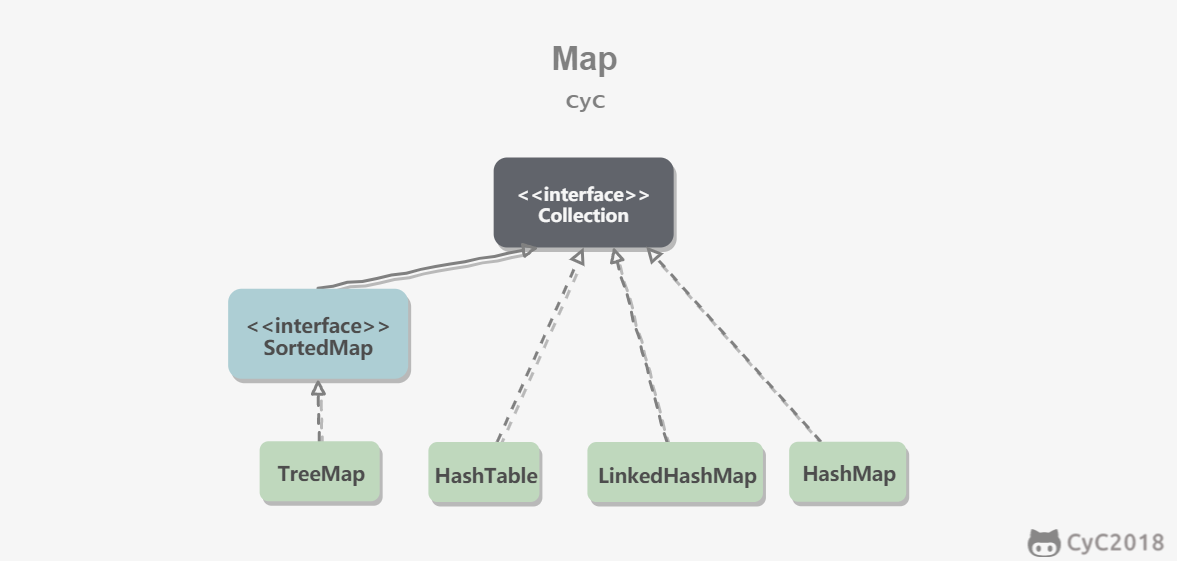
HashMap
HashMap和HashTable的区别:
- 1 HashMap 是线程不安全的 (not synchronised), HashTable 是线程安全的(synchronised)
- 2 HashMap可以有null的key, 存储在第一个桶(null无法计算HashCode), 但是 HashTable 不能有null的key // synchronised: when mutiple threads visit the HashMap, only 1 of them could make modification
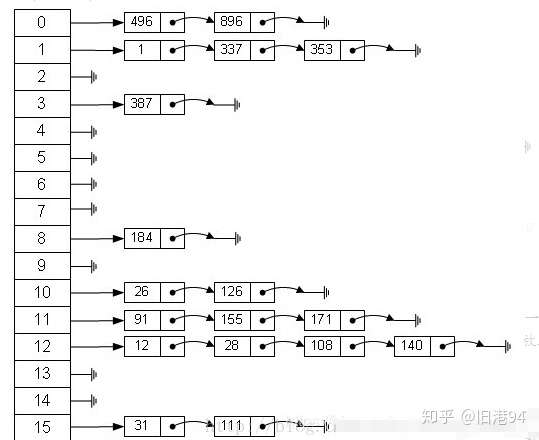
HashMap的底层实现:
- HashMap底层用Array+LinkedList+(红黑树)实现
- 初始化长度为16(如果不传为默认)的数组,每个数组元素存链表的头结点,HashCode对数组长度取余数得到桶下标(在数组中的index)
- 为了防止各个链表长度过长影响get方法,当链表长度达到8时,转为红黑树,提高map效率
- 每个node存储hash, key, value, next
- JDK1.8开始, 插入时采用尾插法将节点插入链表
- JDK1.8开始, 一个桶存储的链表长度大于等于 8 时会将链表转换为红黑树
HashMap出现Hash碰撞怎么处理的(拉链法):
- 用链表存储相同HashCode的键值对
- get的时候根据Key去桶里找,如果是链表说明是冲突的,此时还需要检测Key是否相同
JDK1.8和JDK1.7中HashMap的区别:
- JDK1.8中数据结构转变成了 数组 + 链表 + 红黑树
- JDK1.8采用尾插法, JDK1.7采用头插法, JDK1.7是用单链表进行的纵向延伸,当采用头插法时会容易出现逆序且环形链表死循环问题, 但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。
- JDK1.8扩容时的resize也进行了改进, 因为capacity每次扩展为原来的两倍,所以相当于给hash code顶部增加一位, 如果hash值加入的那一位为0, 那么索引不变, 如果加入的为1, 那么为”原索引 + oldCap”。
HashMap为什么要保证capacity为2的n次方:
- 确定桶下标的最后一步是将 key 的 hash 值对桶个数取模:hash%capacity,如果能保证 capacity 为 2 的 n 次方,那么就可以将这个操作转换为位运算。
- h & (length-1), 表示对数组长度取模, 即只保留length对应二进制位以下的值。
eg:
y : 10110010 x-1 : 00001111 y&(x-1) : 00000010
HashMap为什么是线程不安全的:
HashMap键值对数量超过阈值(capacity(默认16)*loadFactor(默认0.75))时, 整个HashMap会resize(桶扩大为2倍数量), 所有元素会被迁移到新桶。这是多线程操作可能会出现环形链表, 导致get的时候出现死循环。
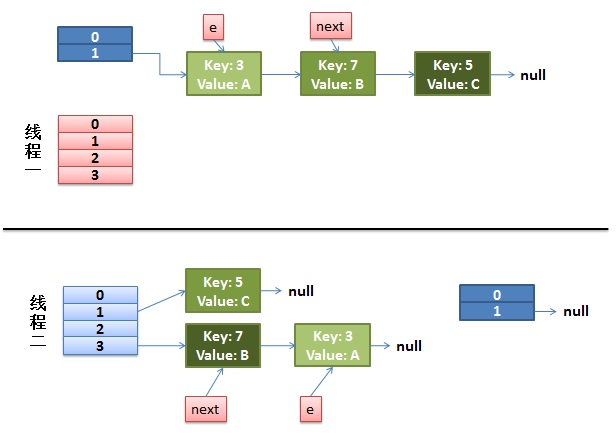
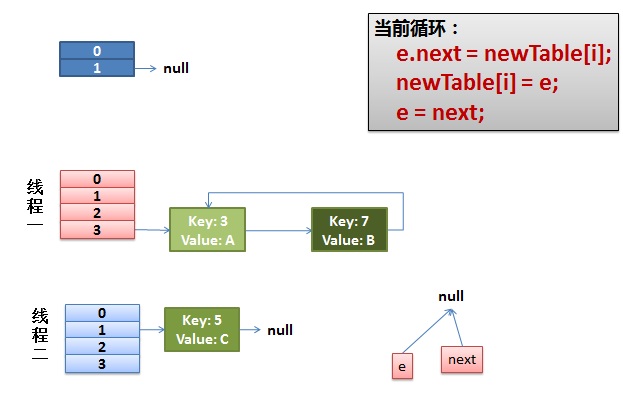
ConcurrentHashMap
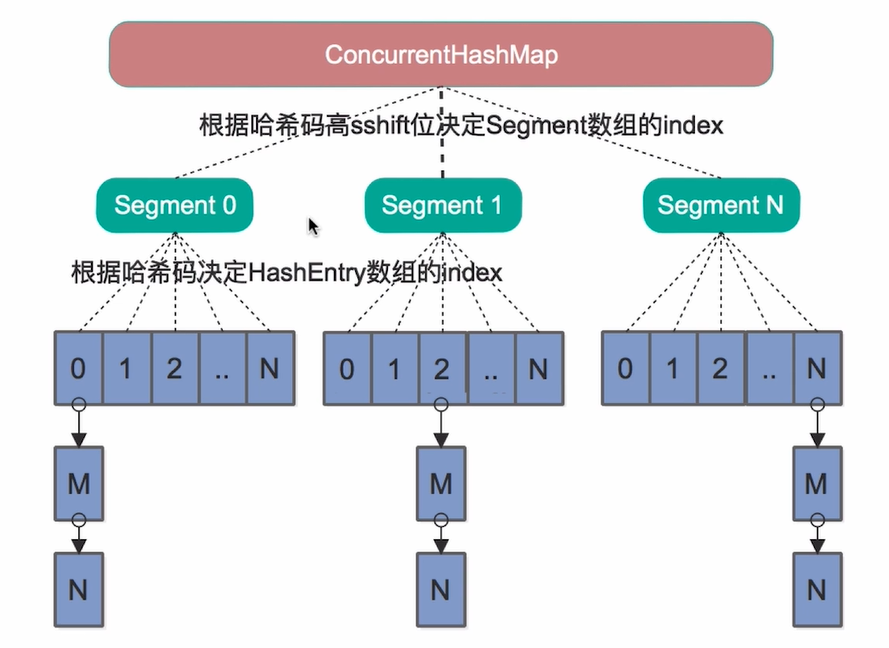
JDK1.7中为了提高并发性能采用了分段的设计, 在每个Segment上加ReentrantLock实现的线程安全线。这种基于Segment和ReetrantLock的设计相对HashTable来说大大提高了并发性能。也就是说多个线程可以并发的操作多个Segment,而HashTable是通过给每个方法加Synchronized即将多线程串行而实现的。所以在一定程度上提高了并发性能。但是这种性能的提升表现相对JDK8来说显得不值一提。
JDK8中ConcurrentHashMap采用的是CAS+Synchronized锁并且锁粒度是每一个桶。简单来说JDK7中锁的粒度是Segment,JDK8锁粒度细化到了桶级别。可想而知锁粒度是大大提到了。辅之以代码的优化,JDK8中的ConcurrentHashMap在性能上的表现非常优秀。
HashTable
和 HashMap 类似,但它是线程安全的,但是它用Syncronized将每一个方法都加锁, 开销很大。它是遗留类,不应该去使用它,而是使用 ConcurrentHashMap 来支持线程安全,ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。与HashMap不同的是, 它不允许null键值对的出现
TreeMap
实现了sortedMap接口, key是排序好的, 基于红黑树实现。
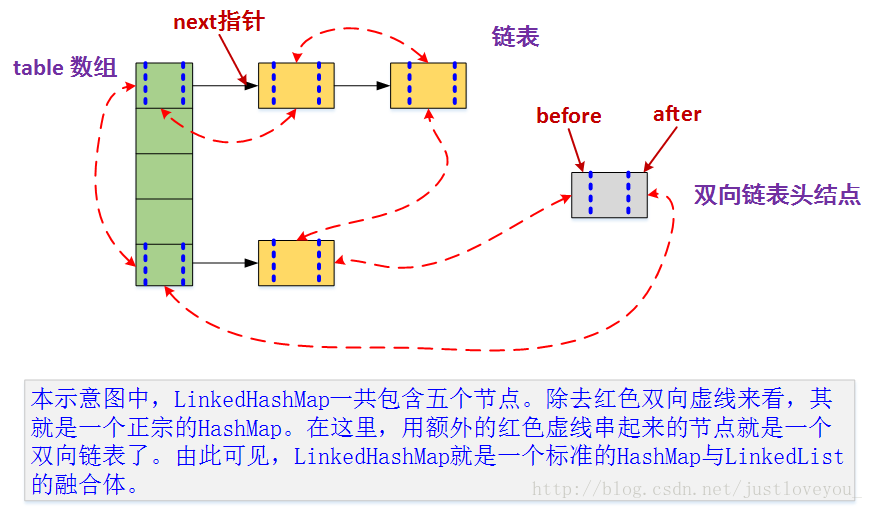
LinkedHashMap
使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
HashMap中预留了3个空函数给LinkedHashMap, 后者做了重写
// Callbacks to allow LinkedHashMap post-actions void afterNodeAccess(Node<K,V> p) { } void afterNodeInsertion(boolean evict) { } void afterNodeRemoval(Node<K,V> p) { }afterNodeAccess: 当一个节点被访问时,如果 accessOrder 为 true,则会将该节点移到链表尾部。也就是说指定为 LRU 顺序之后,在每次访问一个节点时,会将这个节点移到链表尾部,保证链表尾部是最近访问的节点,那么链表首部就是最近最久未使用的节点。
afterNodeInsertion: 在 put 等操作之后执行,当 removeEldestEntry() 方法返回 true 时会移除最晚的节点,也就是链表首部节点 first。(一般是缓存数量超过上限时进行删除, 该方法默认返回false)
afterNodeRemoval: 移除节点后, 断开节点与其他节点的link
使用LinkedHashMap实现LRU
- 设定最大缓存空间 MAX_ENTRIES 为 3;
- 使用 LinkedHashMap 的构造函数将 accessOrder 设置为 true,开启 LRU 顺序;
- 覆盖 removeEldestEntry() 方法实现(默认false,即一直添加不会有删除),重写后, 在节点多于 MAX_ENTRIES 就会将最近最久未使用的数据移除。
class LRUCache<K, V> extends LinkedHashMap<K, V> { private static final int MAX_ENTRIES = 3; protected boolean removeEldestEntry(Map.Entry eldest){ return size() > MAX_ENTRIES; } LRUCache() { super(MAX_ENTRIES, 0.75f, true); } } public static void main(String[] args) { LRUCache<Integer, String> cache = new LRUCache<>(); cache.put(1, "a"); cache.put(2, "b"); cache.put(3, "c"); cache.get(1); cache.put(4, "d"); System.out.println(cache.keySet()); }
Map<Character,Integer> dic=new Hashmap<>();
Map<Character,Integer> dic2=new TreeMap<>();
Map<Character,Integer> dic3=new LinkedHashMap<>();
dic.get('a'); #如果key不存在, 返回null
dic.put('b',1); #存入pair(b,1),如果key已存在则更新
dic.getOrDefault('a',0) #如果'a'不存在,取0
dic.containsKey('a'); #判断'a'是否是dic中的key
dic.size(); #返回dic中pairs个数
dic.remove('a'); #删除dic中key为'a'的pair
dic.clear(); #清空HashMap
dic.keySet(); #以Set形式返回所有的key
Set<Character> keys=dic.keySet();
dic.values(); #返回一个包含values的collection集合,可以进一步转型存储
List<Integer> values=new ArrayList<Integer>(dic.values());
抽象类(abstract class)和接口(Interface)
抽象类
抽象类和抽象方法都使用 abstract 关键字进行声明。如果一个类中包含抽象方法,那么这个类必须声明为抽象类。
抽象类和普通类最大的区别是,抽象类不能被实例化,只能被继承。
接口
接口是抽象类的延伸,在 Java 8 之前,它可以看成是一个完全抽象的类,也就是说它不能有任何的方法实现。Java 8 开始, 接口也可以拥有默认的方法实现,这是因为不支持默认方法的接口的维护成本太高了。在 Java 8 之前,如果一个接口想要添加新的方法,那么要修改所有实现了该接口的类,让它们都实现新增的方法。
interface 的默认方法在其实现类中可以不实现直接使用, 也可以重写实现。
interface 的方法必须是public
interface 的成员变量必须是 static 和 final 类型的example:
public interface VideoService { public default void test(){ System.out.println("this is default method"); } }在实现类中, test()方法可以被其他方法直接调用, 也可以直接被对象调用
- 相同点:
- 抽象类和接口都不能够实例化,但可以定义抽象类和接口类型的引用。
- 不同点:
- 抽象类中可以定义构造器,可以有抽象方法和具体方法,而接口中不能定义构造器而且其中的方法全部都是抽象方法。
- 抽象类中的成员可以是private、默认、protected、public的,而接口中的成员全都是public的。
- 抽象类中可以定义成员变量,而接口中定义的成员变量实际上都是常量(static final)。
- 抽象类只能单继承, 而接口可以多实现
重写与重载
重写
重写应满足的条件:
1 子类方法访问权限为 public,大于父类的 protected。
2 子类的返回类型为 ArrayList,是父类返回类型 List 的子类。
3 子类抛出的异常类型为 Exception,是父类抛出异常 Throwable 的子类。
4 子类重写方法使用 @Override 注解,从而让编译器自动检查是否满足限制条件。class SuperClass { protected List<Integer> func() throws Throwable { return new ArrayList<>(); } } class SubClass extends SuperClass { @Override public ArrayList<Integer> func() throws Exception { return new ArrayList<>(); } }重写方法的调用:
在调用一个方法时,先从本类中查找看是否有对应的方法,如果没有再到父类中查看,看是否从父类继承来。否则就要对参数进行转型,转成父类之后看是否有对应的方法。总的来说,方法调用的优先级为:
this.func(this)
super.func(this)
this.func(super)
super.func(super)/* A | B | C | D */ class A { public void show(A obj) { System.out.println("A.show(A)"); } public void show(C obj) { System.out.println("A.show(C)"); } } class B extends A { @Override public void show(A obj) { System.out.println("B.show(A)"); } } class C extends B { } class D extends C { }public static void main(String[] args) { A a = new A(); B b = new B(); C c = new C(); D d = new D(); // 在 A 中存在 show(A obj),直接调用 a.show(a); // A.show(A) // 在 A 中不存在 show(B obj),将 B 转型成其父类 A a.show(b); // A.show(A) // 在 B 中存在从 A 继承来的 show(C obj),直接调用 b.show(c); // A.show(C) // 在 B 中不存在 show(D obj),但是存在从 A 继承来的 show(C obj),将 D 转型成其父类 C b.show(d); // A.show(C) }重载
同一个类中存在多个名称相同的方法,但是参数类型、个数、顺序至少有一个不同。 调用时根据对应的参数调用对应的方法。
应该注意的是,返回值不同,其它都相同不算是重载。
class MyClass { int height; MyClass() { System.out.println("无参数构造函数"); height = 4; } MyClass(int i) { System.out.println("房子高度为 " + i + " 米"); height = i; } void info() { System.out.println("房子高度为 " + height + " 米"); } void info(String s) { System.out.println(s + ": 房子高度为 " + height + " 米"); } } public class MainClass { public static void main(String[] args) { MyClass t = new MyClass(3); //房子高度为 3 米 t.info(); //房子高度为 3 米 t.info("重载方法"); //重载方法: 房子高度为 3 米 //重载构造函数 new MyClass(); //无参数构造函数 } }
Switch不能使用的数据类型
Java switch底层都是比较的int, String也是转换成ASCII码进行的对比
不支持的类型有:
- float, double: 精度损失导致对比不准确
- long: long的范围比int大
- boolean: 应该直接使用if else
java与C++的区别
- Java 是纯粹的面向对象语言,所有的对象都继承自 java.lang.Object,C++ 为了兼容 C 即支持面向对象也支持面向过程。
- Java 通过虚拟机从而实现跨平台特性,但是 C++ 依赖于特定的平台。
- Java 没有指针,它的引用可以理解为安全指针,而 C++ 具有和 C 一样的指针。
- Java 支持自动垃圾回收,而 C++ 需要手动回收。
- Java 不支持多重继承,只能通过实现多个接口来达到相同目的,而 C++ 支持多重继承。
- Java 不支持操作符重载,虽然可以对两个 String 对象执行加法运算,但是这是语言内置支持的操作,不属于操作符重载,而 C++ 可以。
- Java 的 goto 是保留字,但是不可用,C++ 可以使用 goto。